I’ve been wanting to play around with recent technologies and approaches used in building LLM-powered applications - one interesting idea that came to mind was an assistant to generate DAX. Now, this could be done via ChatGPT currently (simply ask it to generate sum of sales for example), but for real assistance the model needs context awareness of how a data model is setup. Here is a sneak peek at the final result and then some details on how I built it.
Design
With the problem/idea, the overall workflow that would be implemented:
- A user could upload a Power BI model.
- The application parses the model and extracts relevant components (tables, columns, relationships) into plain text.
- Additional DAX awareness is added such as formatting suggestions, general rules, etc.
- All this is wrapped up and passed to the LLM along with the user’s question.
- An AI judge is used to score the confidence in the response.
- A testing approach to see how well the LLM performs.
In addition to the above, the goal was to build a custom and extensible app using FastAPI and Vue - common backend and frontend technologies that could be built upon in many different ways.
Backend
API Calls
The first piece to build was a method to stream out API results from our LLM model - Anthropic’s Claude in this case. The function will take in a list of chat interactions structured as follows:
"chat_input_list": [
{
"role": "user",
"message": "What is your name?"
},
{
"role": "assistant",
"message": "My name is Claude"
}
]And then return a stream of text for the model’s response. The FastAPI endpoint will be async, so we’ll try to do as much as possible in an async way for the underlying backend server functions. Anthropic’s API provides AsyncAnthropic client (see examples in their github repo). Setting aside how we do the system prompt for now, putting together these pieces gives us the below function - adding minor data structure parsing to add details to our data model and then making the streaming api call.
Imports and key lookups:
import os
from typing import AsyncGenerator
from anthropic import AsyncAnthropic
from src.llm.system_prompt import get_system_prompt
ANTHROPIC_API_KEY = os.getenv('ANTHROPIC_API_KEY')Function to enhance our data model to meet Anthropic format requirements:
def build_anthropic_message_input(chat_input_list: list) -> list:
"""Builds anthropic message input.
Args:
chat_input_list (list): List of chat inputs to send to the API.
Returns:
list: List of anthropic message input.
"""
message_input = []
for chat_instance in chat_input_list:
message_input.append({
'role': chat_instance['role'],
"content": [
{
"type": "text",
"text": chat_instance['message']
}
]
})
return message_inputFull API Call:
async def anthropic_stream_api_call(chat_input_list: list) -> AsyncGenerator[str, None]:
"""Streams anthropic response.
Args:
chat_input_list (list): List of chat inputs to send to the API.
Yields:
AsyncGenerator[str, None]: Stream of anthropic response.
"""
# Build message list
message_input = build_anthropic_message_input(chat_input_list=chat_input_list)
# Setup and make api call.
client = AsyncAnthropic(api_key=ANTHROPIC_API_KEY)
stream = await client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=4096,
temperature=0.2,
system=get_system_prompt(chat_input_list),
messages=message_input,
stream=True
)
async for event in stream:
if event.type in ['message_start', 'message_delta', 'message_stop', 'content_block_start', 'content_block_stop']:
pass
elif event.type == 'content_block_delta':
yield event.delta.text
else:
yield event.typeWe can wrap this up in a simple FastAPI endpoint to expose to our frontend:
@app.post("/stream")
@limiter.limit("5/second; 30/minute; 500/day")
async def stream_text(request: Request, input: ChatInput):
"""FastAPI endpoint to stream AI-generated text"""
return StreamingResponse(anthropic_stream_api_call(input.chat_input_list), media_type="text/event-stream")System Prompt
One of the key things an LLM-powered app can add is adding context via a well-defined system prompt. In our app, we use a combination of static rules and suggestions plus dynamically retrieved knowledge based on the users question. To start, a list of rules (limited for brevity):
return f"""\
You are a helpful assistant that can answer questions about the DAX language.
You are given a user prompt where the user is a Power BI developer that is unsure of the proper DAX calculation to use.
Your task is to answer the user prompt using the DAX language.
...(additional prompts here)
Here are some functions that might be relevant to the user prompt:
{dax_functions}
"""This continues to list various rules about formatting, some helpful DAX principles, etc. The last line where text appends specific documentation around which DAX functions may be useful is critical. If a user asks a question - which DAX functions might be best to use? If we can determine this, we can use an embedding model to lookup the closest functions. Two files are used to accomplish this - the first contains a json structure as follows:
{
"function": "AVERAGE",
"description": "Returns the average (arithmetic mean) of all the numbers in a column."
},
...(all other dax functions)The second contains more detailed information on each function including parameter inputs, examples, etc.
With the user’s question and this knowledge base of lookup data, an open source model is used to grab the most relevant functions. The full function is excluded for brevity, but applying model.encode on the user’s input + each function detail gives a numerical representation to then call semantic_search to find the best matches. For example, if the user is asking for an average, then various dax functions related to calculating averages will float to the top as the best matches - and appended dynamically to the system prompt. This allows us to keep the reference material relevant, but concise to best help the model.
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import semantic_search
# Load model
model = SentenceTransformer(
"sentence-transformers/all-MiniLM-L6-v2",
cache_folder='src/model_download_cache'
)Evaluation
The last major piece the backend is responsible for is evaluation - both realtime judging of responses as well as a scoring methodology.
AI as a realtime judge
For a realtime judge, we utilize a very similar call to the LLM model, but this time instruct it to judge the response on a scale from 1-10 on how well it meets the users question. High level:
- User asks AI to generate DAX code.
- Backend wraps up relevant context and gets back a response with the proposed code.
- A separate and independent LLM with a new system prompt (“You are a judge of DAX code generation responses. You should only return full numbers and no other text allowed…”) acts as a judge - given context of the original question and response is asked to rate how confidently the DAX code answers the question.
Scoring
For benchmarking, how could we score how well the AI responses are? One idea is to have a reference set of questions - a handful of questions generated by an expert user with the result against a model evaluated. For this - a toy “Contoso” data model was developed and a few measures built. The numerical result was retrieved and then this can be compared against the results of the DAX code the model returns.
The key point here - rather than judging the dax code accuracy directly (can be done ad hoc, but difficult in bulk), we can execute the exact DAX code from an expert vs. the model for a static set of questions to come up with a percentage score. Similar to taking a test, the AI model takes a “test” to see how accurate the generated DAX code is. Building the questions and answers is time-consuming, but the actual taking of the test (connecting to a Power BI model, running DAX code, checking the result) can all be automated and repeated.
Frontend
The frontend is as follows - a simple chat interface that I built with vue, notably with the addition to upload a PBIT file.
Initial Chat UI
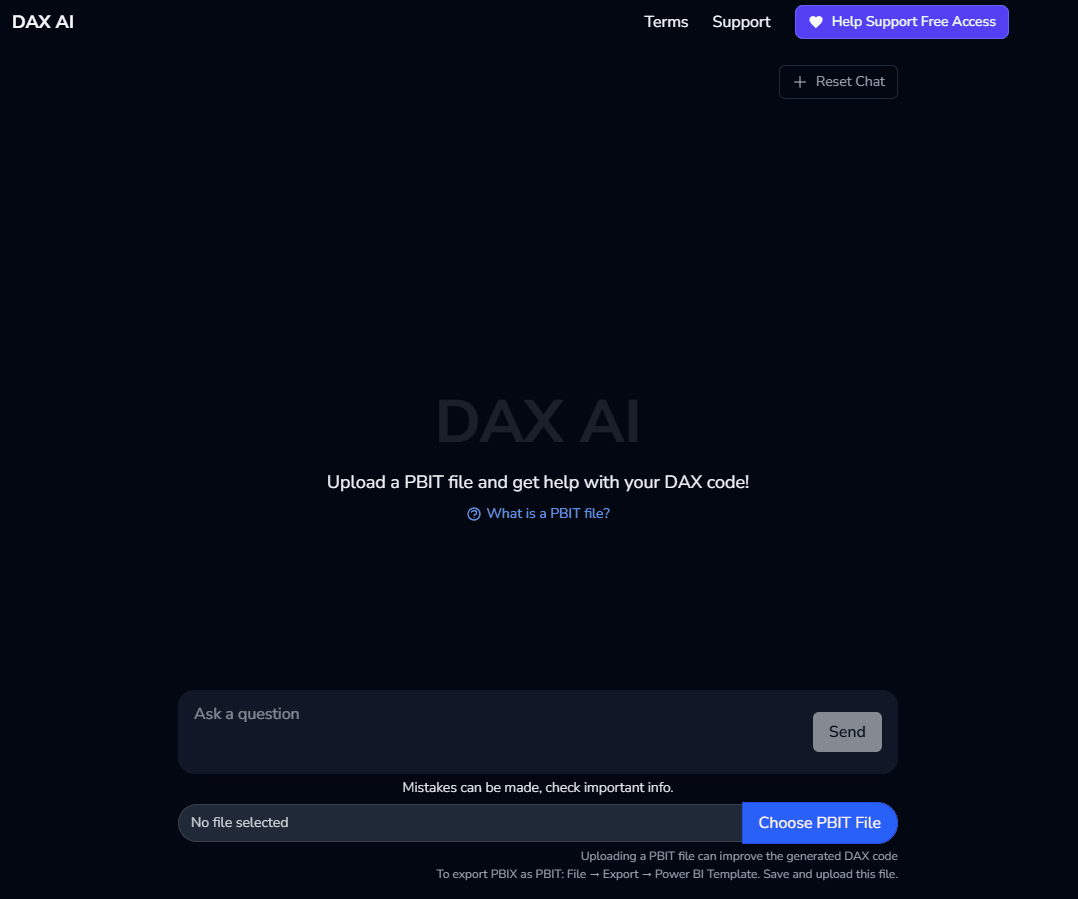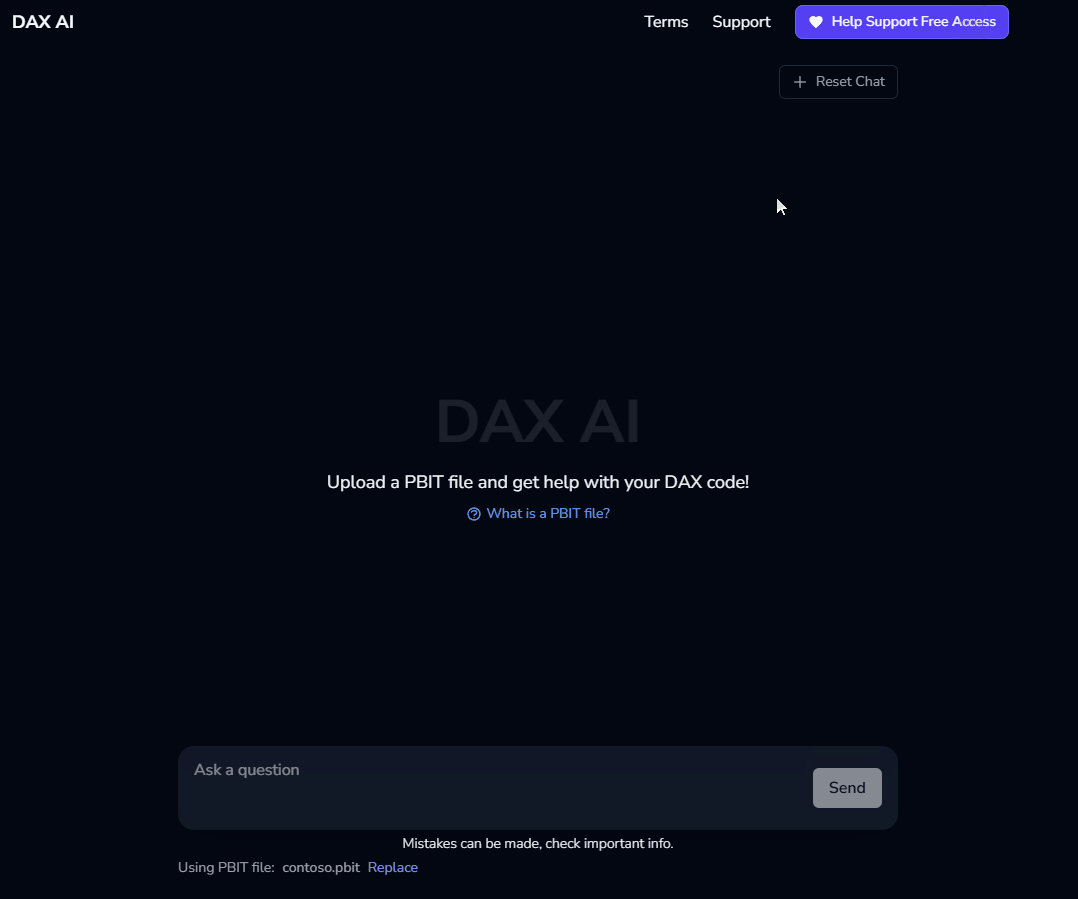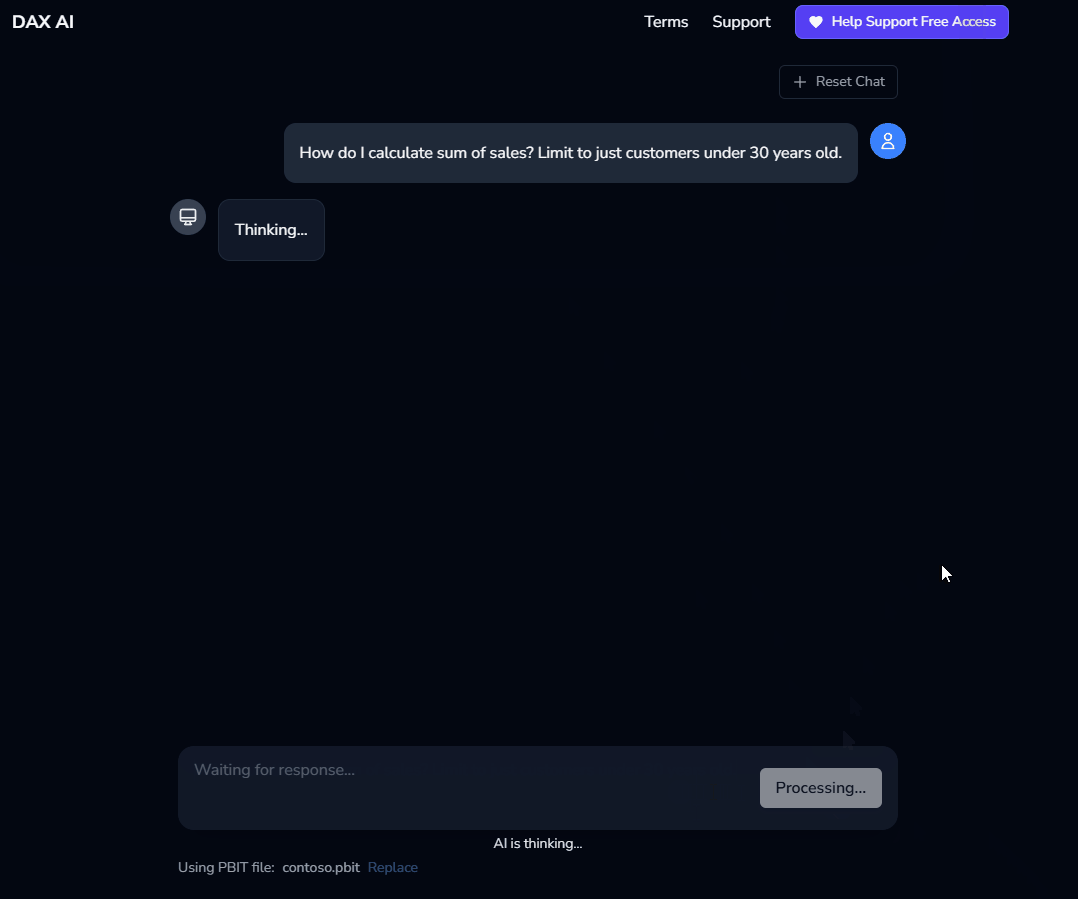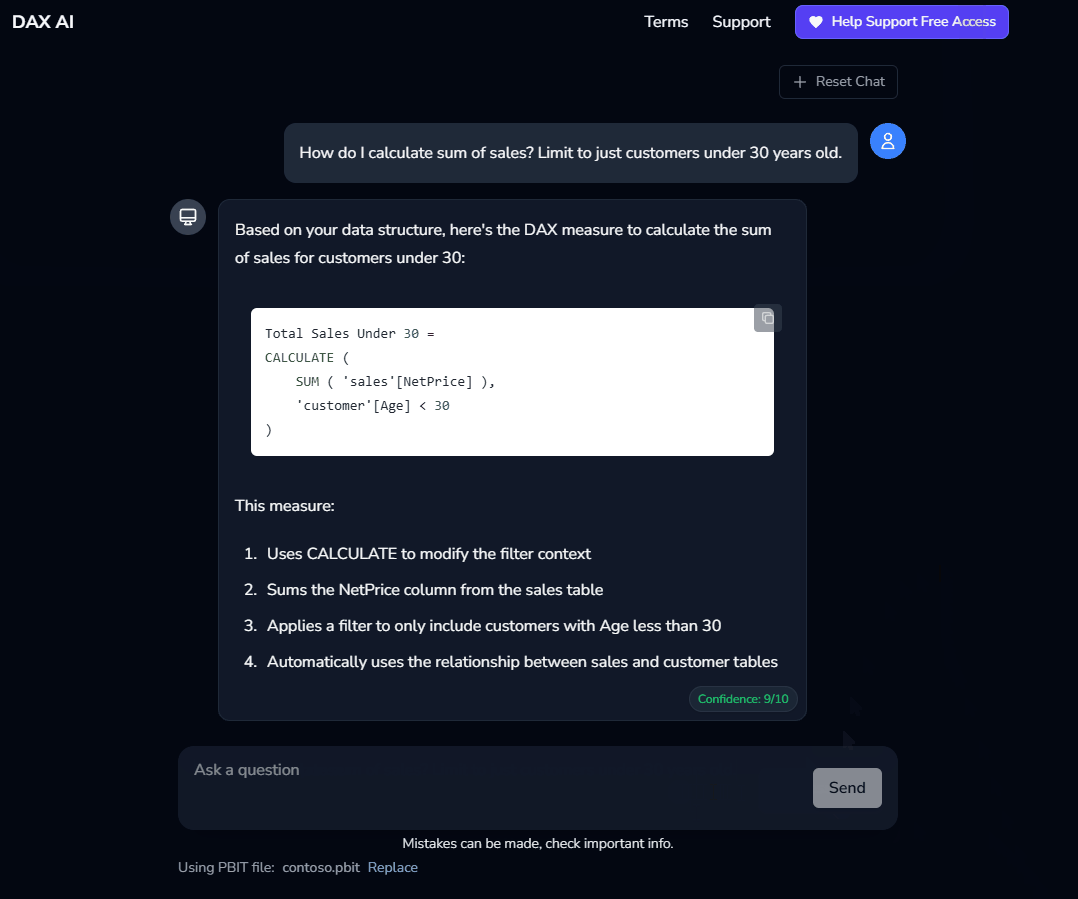
The PBIT file allows for the data model to be parsed and sent along with the question. When you take a Power BI data model and save it as a “PBIT” file, unzipping the directory provides files that define things like tables, columns, and relationships. This data is stored in a json structure - once the file is uploaded the json is parsed and then those model details are included along with the original question in that first API call. Finally, once the answer is returned, the follow-on AI judge request is sent to display a confidence score. An example question loop looks as follows:
Summary
Foundation model APIs and LLMs provide a number of new opportunities to develop AI-powered applications. In this case, a combination of a few different approaches to augment a developer’s workflow allows a more streamlined experience. Uploading a model with a click of a button and providing popular LLMs with supplemental info - tailoring response to exactly what is needed.
All examples and files available on Github: Backend and Frontend.