
Unstructured text data requires unique steps to preprocess in order to prepare it for machine learning. This article walks through some of those steps including tokenization, stopwords, removing punctuation, lemmatization, stemming, and vectorization.
Dataset Overview
To demonstrate some natural language processing text cleaning methods, we’ll be using song lyrics from one of my favorite musicians - Jimi Hendrix. The raw song lyric data can be found here. For the purposes of this demo, we’ll be using a few lines from his famous song The Wind Cries Mary:
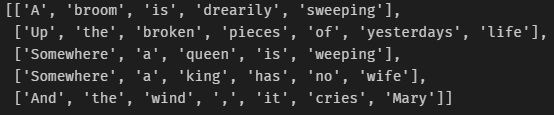
A broom is drearily sweeping
Up the broken pieces of yesterdays life
Somewhere a queen is weeping
Somewhere a king has no wife
And the wind it cries Mary Tokenization
One of the first steps in most natural language processing workflows is to tokenize your text. There are a few different varieties, but at the most basic sense this involves splitting a text string into individual words.
We’ll first review NLTK (used to demo most of the concepts in this article) and quickly see tokenization applied in a couple other frameworks.
NLTK
We’ve read the dataset into a list of strings and can use the word tokenize function from the NLTK python library. You’ll see that looping through each line, applying word tokenize splits the line into individual words and special characters.
from nltk.tokenize import word_tokenize
# Loop through each line of text and tokenize
sample_lines_tokenized = [word_tokenize(line) for line in sample_lines]
Tokenizers In Other Libraries
There are many different ways to accomplish tokenization. The NLTK library has some great functions in this realm, but others include spaCy and many of the deep learning frameworks. Some examples of tokenization in those libraries are below.
Torch
# Pytorch tokenization
from torchtext.data import get_tokenizer
# Initialize object and tokenize each line
pytorch_tokenizer = get_tokenizer("basic_english")
pytorch_tokens = [pytorch_tokenizer(line) for line in sample_lines]spaCy
#spaCy tokenization
from spacy.tokenizer import Tokenizer
from spacy.lang.en import English
# Initialize object and tokenize each line
nlp = English()
spacy_tokenizer = Tokenizer(nlp.vocab)
spacy_tokens = [spacy_tokenizer(line) for line in sample_lines]There can be slight differences from one tokenizer to another, but the above more or less do the same. The spaCy library has its own objects that incorporate the framework’s features, for example returning a doc object instead of a list of tokens.
Stopwords
There may be some instances where removing stopwords improves the understanding or accuracy of a natural language processing model. Stopwords are commonly used words that may not carry much information and may be able to be removed with little information loss. You can get a list of stopwords from NLTK with the following python commands.
Loading and Viewing Stopwords
# Import and download stopwords
from nltk.corpus import stopwords
nltk.download('stopwords')
# View stopwords
print(stopwords.words('english'))
Removing Stopwords
We can create a simple function for removing stopwords and returning an updated list.
def remove_stopwords(input_text):
return [token for token in input_text if token.lower() not in stopwords.words('english')]
# Apply stopword function
tokens_without_stopwords = [remove_stopwords(line) for line in sample_lines_tokenized]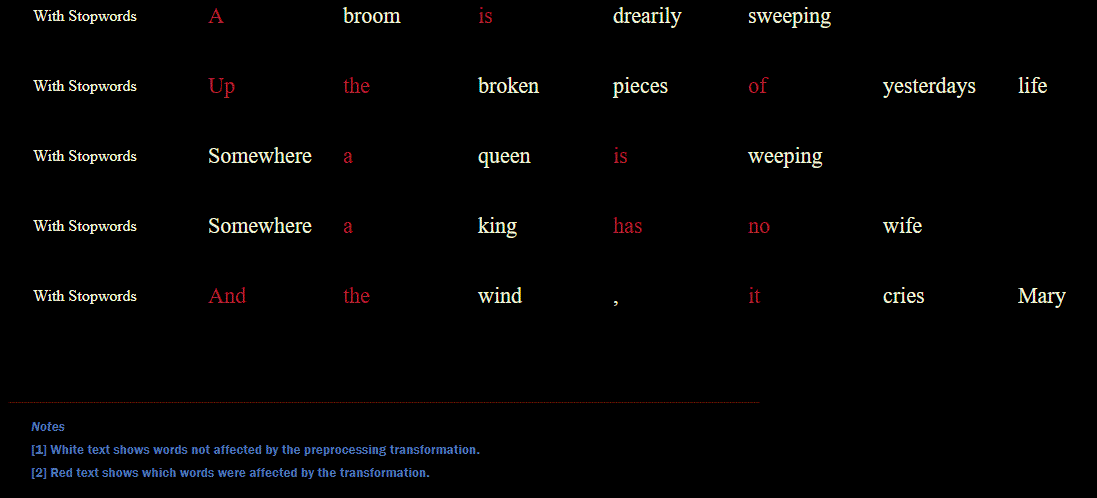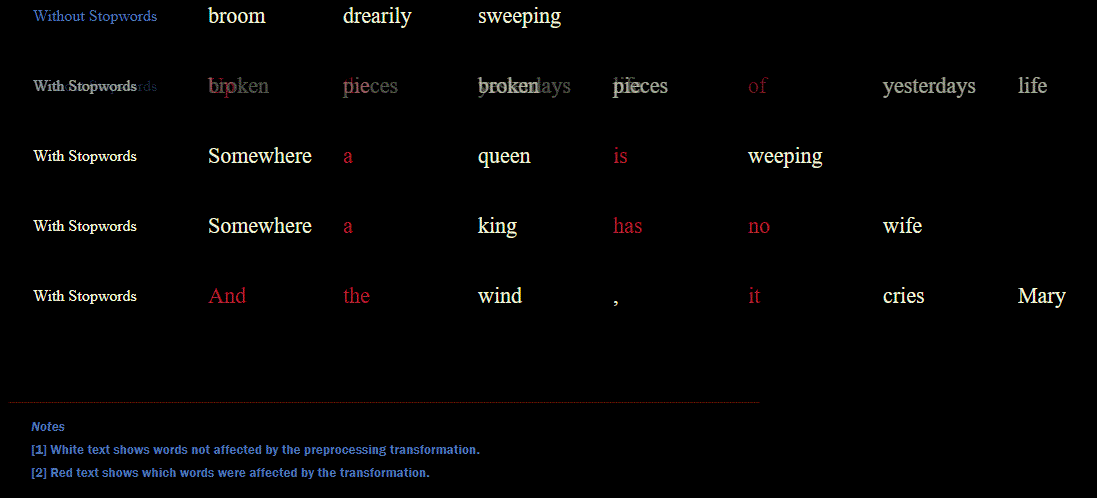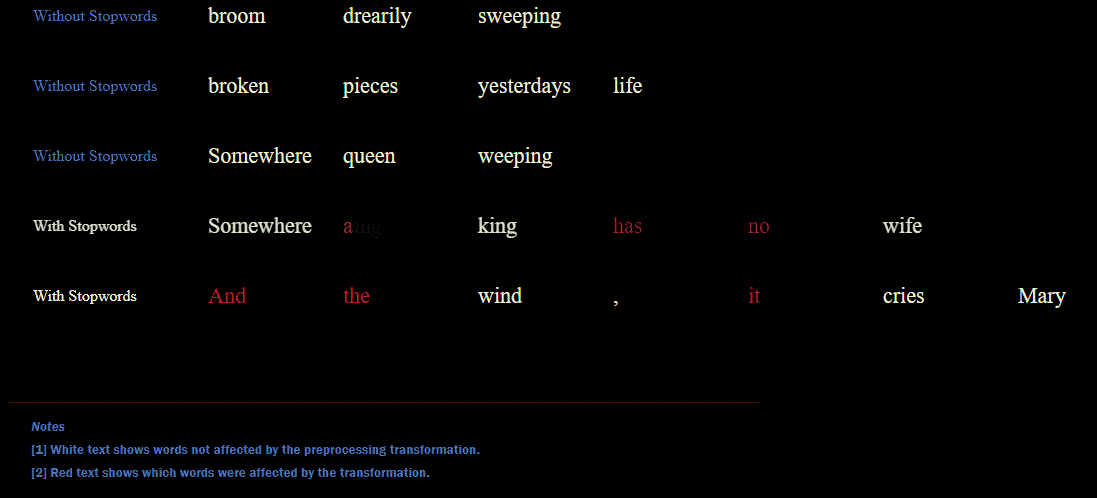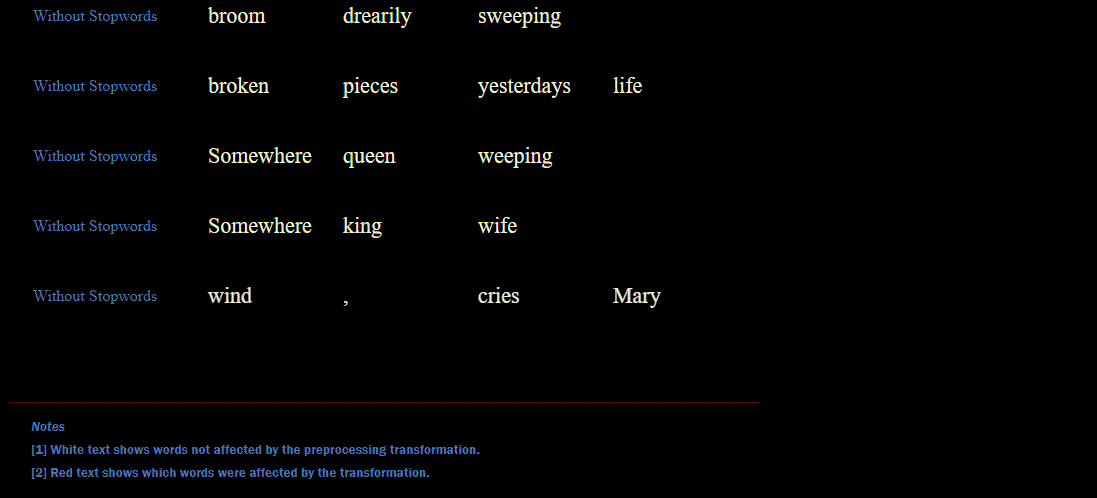
Punctuation
Similar to stopwords, since our text is already split into sentences removing punctuation can be performed without much information loss and to clean up the text to just words. One approach is to simple use the string object list of punctuation characters.
import string
def remove_punctuation(input_text):
return [token for token in input_text if token not in set(string.punctuation)]
# Apply punctuation function
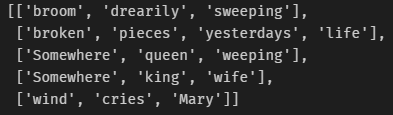
tokens_without_punctuation = [remove_punctuation(line) for line in tokens_without_stopwords]We had one extra comma that is now removed after applying this function:
Lemmatization
We can further standardize our text through lemmatization. This boils down a word to just the root, which can be useful in minimizing the unique number of words used. This is certainly an optional step, in some cases such as text generation this information may be important - while in others such as classification it may be less so.
Testing Lemmatizers
To lemmatize our tokens, we’ll use the NLTK WordNetLemmatizer. One example applying the lemmatizer to the word “cries” yields the root word “cry”.
# Required library imports and downloads
from nltk.stem import WordNetLemmatizer
nltk.download('wordnet', quiet=True)
# Instantiate and test on one word
lem = WordNetLemmatizer()
lem.lemmatize('cries')Output text: cryApply to All Tokens/Parts of Speech
The NLTK function runs on specific parts of speech, so we’ll loop through these in a generalized function to lemmatize tokens.
def lemmatize(input_text):
# Instantiate class
lem = WordNetLemmatizer()
# Lemmatized text becomes input inside all loop runs
lemmatized_text = input_text
# Lemmatize each part of speech
for part_of_speech in ['n', 'v', 'a', 'r', 's']:
lemmatized_text = [lem.lemmatize(token, part_of_speech).lower() for token in lemmatized_text]
return lemmatized_text
# Apply lemmatize function
tokens_lemmatized = [lemmatize(line) for line in tokens_without_punctuation]
Stemming
Stemming is similar to lemmatization, but rather than converting to a root word it chops off suffixes and prefixes. I prefer lemmatization since it is less aggressive and the words still are valid; however, stemming is also still sometimes used so I show how here.
Snowball Stemmer
There are many different flavors of stemming algorithms, for this example we use the SnowballStemmer from NLTK. Applying stemming to “sweeping” removes the suffix and yields the word “sweep”.
# Required improts
from nltk.stem import SnowballStemmer
# Instantiate and test on one word
stemmer = SnowballStemmer('english')
stemmer.stem('sweeping')Output text: sweepApply to All Tokens
Similar to past steps, we can create a more generic function and apply this to each line.
def stem(input_text):
stemmer = SnowballStemmer('english')
return [stemmer.stem(token) for token in input_text]
# Apply stemming function
tokens_stemmed = [stem(line) for line in tokens_without_punctuation]
As you can see, some of these are not words. For this reason, I prefer to go with lemmatization in almost all cases so that word lookups during embedding is more successful.
Put it all together
We’ve went through a number of possible steps to clean our text and created functions for each while doing so. One final step would be combining this into one simple and generalized function to run on the text. I wrapped the functions in one combined function that allows enabling of any desired function and to run each sequentially on the various lines of text. I used a functional approach below, but a class could certainly be built as well using similar principles.
def clean_list_of_text(
input_text,
enable_stopword_removal=True,
enable_punctuation_removal=True,
enable_lemmatization=True,
enable_stemming=False
):
# Get list of operations
enabled_operations = [word_tokenize]
if enable_stopword_removal:
enabled_operations.append(remove_stopwords)
if enable_punctuation_removal:
enabled_operations.append(remove_punctuation)
if enable_lemmatization:
enabled_operations.append(lemmatize)
if enable_stemming:
enabled_operations.append(stem)
print(f'Enabled Operations: {len(enabled_operations)}')
# Run all operations
cleaned_text_lines = input_text
for operation in enabled_operations:
# Run for all lines
cleaned_text_lines = [operation(line) for line in cleaned_text_lines]
return cleaned_text_lines
# Example of applying the function
clean_list_of_text(sample_lines, enable_stopword_removal=True, enable_punctuation_removal=True, enable_lemmatization=True)Vector Embedding
Now that we finally have our text cleaned, is it ready for machine learning? Not quite. Most models require numeric inputs rather than strings. In order to do this, embeddings where strings are converted into vectors are often used. You can think of this as numerically capturing the information and meaning of text in a fixed length numerical vector.
We’ll walk through an example of using gensim; however, many of the deep learning frameworks may have ways to quickly load pre-trained embeddings as well.
Gensim Pre-Trained Model Overview
The library that we’ll be using to lookup pre-trained embedding vectors for our cleaned tokens is gensim. They have multiple pre-trained embeddings available for download, you can review these in the word2vec module inline documentation.
import gensim.downloader
# Load pretrained gensim model
glove_model = gensim.downloader.load("glove-wiki-gigaword-100")Most Similar Words
Gensim provides multiple functionalities to use with the pre-trained embeddings. One is viewing which words are most similar. To get an idea of how this works, let’s try the word “queen” which is contained in our sample Jimi Hendrix lyrics.
# Show default most similar words given a word
glove_model.most_similar('queen')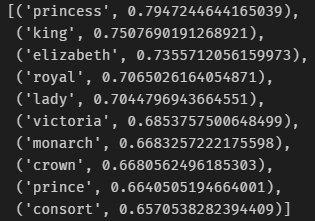
Retrieving Vector Embedding Example
To convert a word to embedding vector we simply use the pre-trained model like a dictionary. Let’s see what the embedding vector looks like for the word “broom”.
# Sample of embedding vector for a word
glove_model['broom']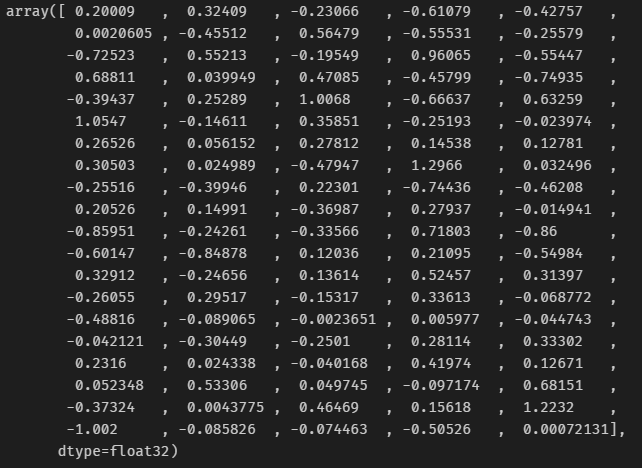
Apply to All Tokens
Similar to past steps, we can simply loop through the cleaned tokens and build out a list converting to vectors instead. In reality, there is likely some error handling for words that don’t lookup successfully (and cause a key error since it is missing from the dictionary), but I’ve omitted that in this simple example.
# Convert all lines and tokens to vectors using our glove_model object
vectors = [[glove_model[token] for token in line] for line in text_to_convert]Padding Vectors
Many natural language processing models require the same number of words as inputs. However, text length is often ragged, with each line not conforming to the exact same number of words. To fix this, one approach often taken is padding sequences. We can add dummy vectors at the end of the shorter sentences to get everything aligned.
Padding Sequences in Pytorch
Many libraries have helper methods for this type of workflow. For example, torch allows us to pad sequences in this manner as follows.
# Example of padding those embeddings and converting to torch tensor (num_examples, sequence_length, embed_dim)
torch_padded_tensor = torch.nn.utils.rnn.pad_sequence([torch.FloatTensor(vector) for vector in vectors], batch_first=True)
torch_padded_tensor.shapeOutput: torch.Size([5 4 100])After padding our sequences, you can now see that the 5 lines of text are each of length 4 with an embedding dimension of 100 as expected. But what happened to our first line which only had three words (tokens) after cleaning?
Viewing Padded Vectors
Torch by default just creates zero value vectors for anything that needs to be padded.
# What is the 4th word in the first line shown as, since it didn't exist
torch_padded_tensor[0][3]
Summary
Text data often requires unique steps when preparing data for machine learning. Cleaning text is important to standardize words to allow for embeddings and lookups, while losing the least amount of information possible for a given task. Once you’ve cleaned and prepared text data, it can be used for more advanced machine learning workflows like text generation or classification.
All examples and files available on Github.